Microservice Design Patterns: Aggregator
June 17, 2019
The aggregator design pattern is a simple way of providing a single, unified service capable of surfacing data from multiple microservices, and a commonly used pattern when implementing a microservice-based architecture.
Let’s imagine that we’ve been tasked with developing an internal API for our organisation - a general practice clinic. The API needs to consume data from three existing microservices, each of which is used by other services within the practice’s architecture - some services call these individually, some call all three.
The requirements for the API are that it should return simple details for a patient, a list of their allergies and a list of medication that they are currently taking.
Our three existing microservices are as follows:
- Existing Service #1 returns details about a patient - their name, age, etc.
- Existing Service #2 returns a list of allergies that the patient has.
- Existing Service #3 returns a list of medication that the patient is currently taking.
Usually, we’d expect an aggregator to make synchronous calls to relevant microservices, performing any necessary business logic on each result as it receives it and then packaging this up as an API endpoint for a consumer to use. This meets our requirements whilst opening up potential for re-use and decoupling.
Rather than increasing the number of services which call these microservices directly, we can make use of the aggregator pattern here.
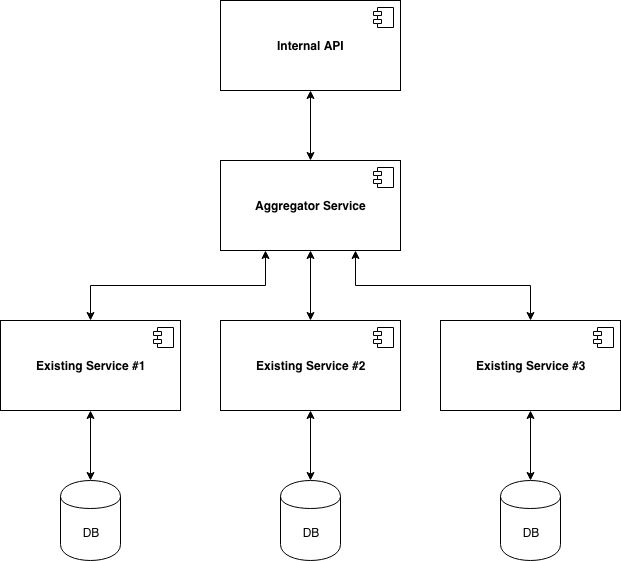
Our new internal API will call our new aggregator microservice, which will call the three existing microservices before then pushing the necessary results back up to the internal API.
We can re-use our aggregator within other services which call all three existing services, decoupling these from direct interaction with the microservices, which will make it easier to replace one later down the line; if we want to suddenly commission a new allergies microservice, we only have to update the aggregator (and those services which don’t call all three existing services).